TurboQuant: The Algorithm That Crashed Memory Stocks (And What It Actually Means for AI)
Google just released a compression breakthrough that cut AI memory needs by 6x with zero accuracy loss. Wall Street panicked. Here's what's really happening — and why builders should care.

Today, Micron fell 5%, SanDisk dropped 8%, and the Nasdaq slid 2.4%.
The proximate cause: a research paper from Google called TurboQuant.
Not a new chip. Not a new model. A compression algorithm — a piece of math that changes how AI models handle their working memory during inference. And it does it so well that Wall Street decided the entire memory chip industry might be in trouble.
That's probably an overreaction. But TurboQuant itself is a genuine breakthrough worth understanding, because it has direct implications for anyone running AI workloads — including agentic systems.
Let me break it down
.
The Problem: AI Has a Memory Addiction
When a large language model generates text, it doesn't just use its weights (the trained parameters). It also maintains something called a KV cache — a Key-Value cache that stores the "working memory" of the current conversation.
Think of it like RAM vs. a hard drive. The model's weights are the hard drive (permanent knowledge). The KV cache is the RAM — the live working memory that tracks everything said in the conversation so far.
Here's the problem: the KV cache grows with every token of context. A 100K-token conversation (roughly 75,000 words) generates an enormous KV cache that must be kept in high-bandwidth memory (HBM) — the expensive memory on AI chips. This creates two constraints:
Memory capacity: Long contexts require enormous amounts of HBM
Memory bandwidth: Fetching KV cache data is the bottleneck for inference speed
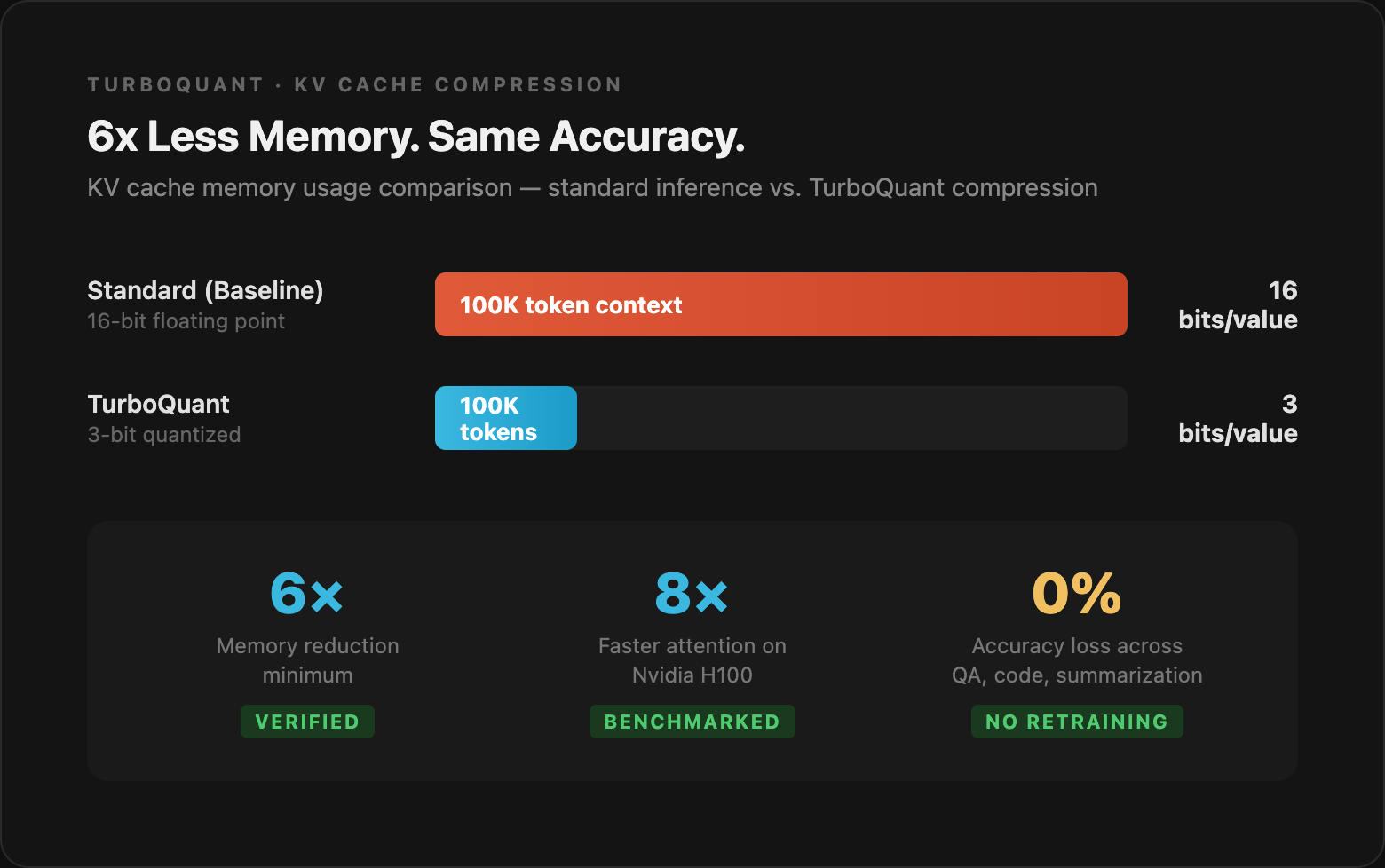
Traditional KV caches store each value in 16-bit floating point format. That's the baseline TurboQuant is beating.
What TurboQuant Does
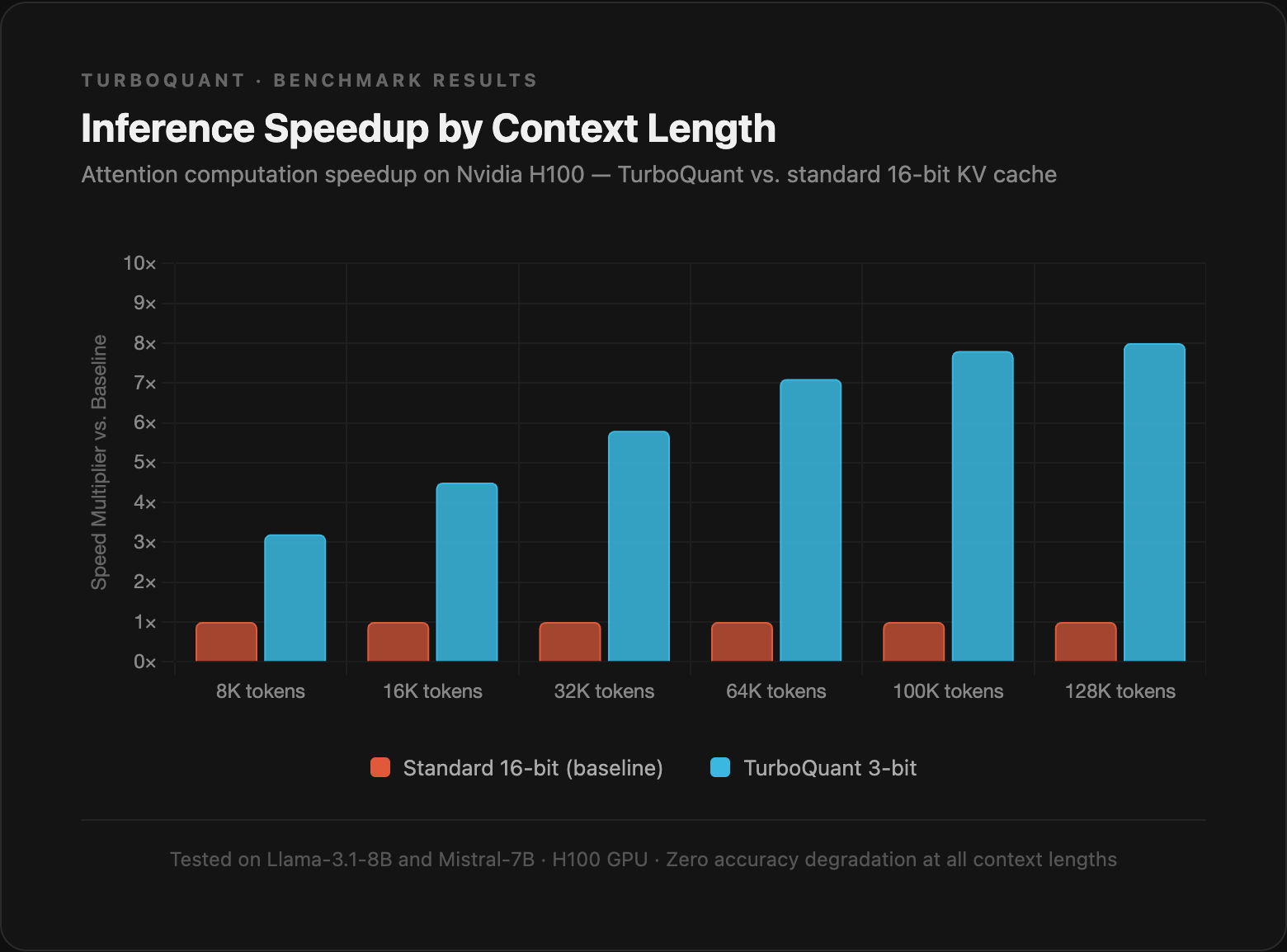
TurboQuant compresses KV cache values from 16 bits down to 3 bits — an 83% reduction in storage size — with zero measurable accuracy loss across question answering, code generation, and summarization benchmarks.
The headline numbers:
6x lower memory usage (at minimum)
Up to 8x faster attention computation on Nvidia H100 GPUs
Zero accuracy loss on LongBench, needle-in-a-haystack, and other standard evals
No retraining required — works with existing models out of the box
How It Works (The Simple Version)
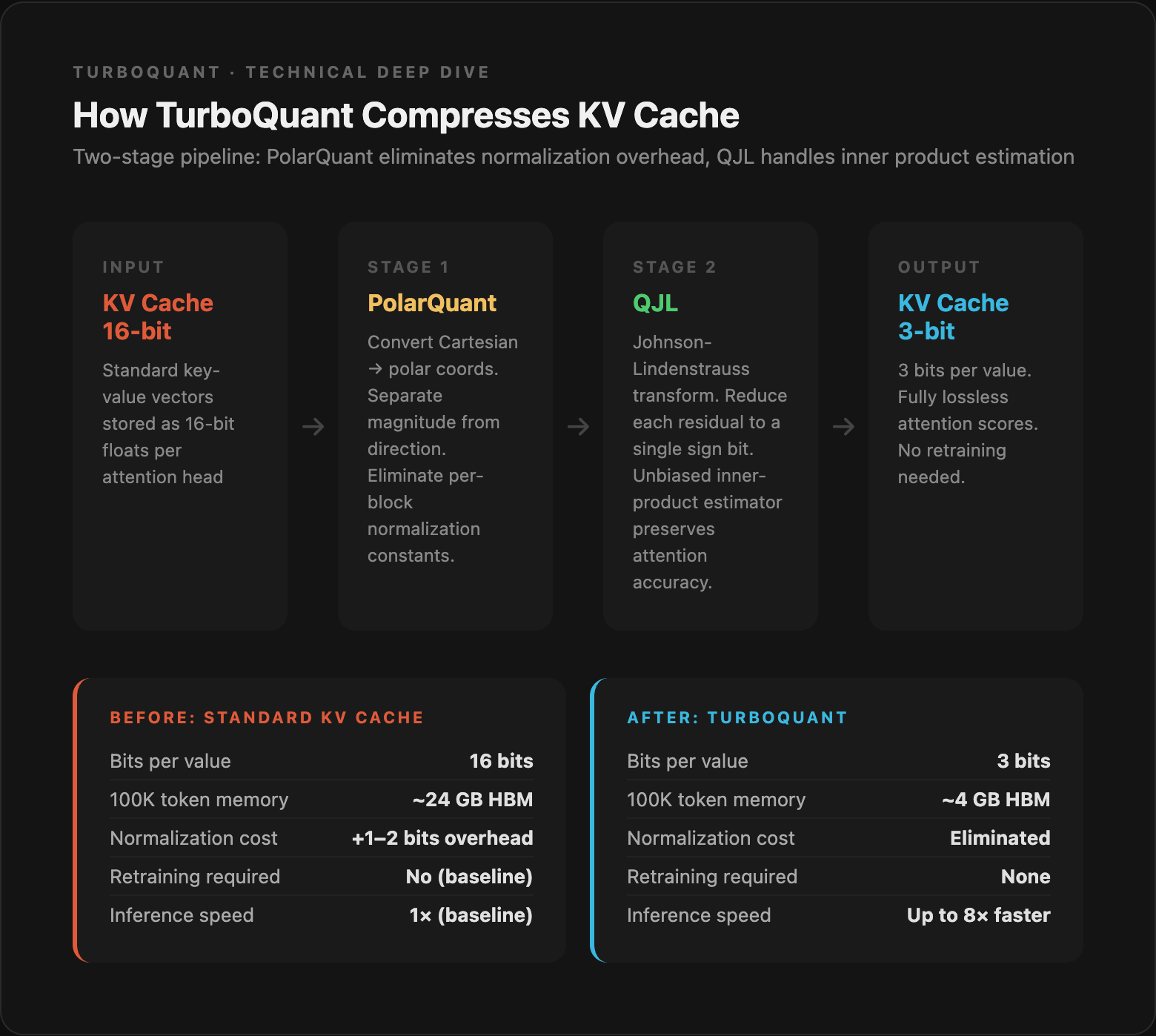
TurboQuant combines two companion techniques: PolarQuant and QJL (Quantized Johnson-Lindenstrauss).
PolarQuant solves a problem that plagued earlier compression methods. Traditional quantizers need to store a normalization constant per block of data — think of it as a conversion factor that lets you decode the compressed values. That constant typically costs 1-2 extra bits per value, eating into your compression gains.
PolarQuant eliminates this overhead by converting vectors from Cartesian to polar coordinates. Instead of storing (x, y, z) style components, it stores the magnitude and direction separately. Because the angular distributions are mathematically predictable, you can skip the per-block normalization entirely.
QJL handles the inner product estimation problem. When the attention mechanism needs to look up stored memories, it computes inner products between the query and the compressed keys. QJL uses a Johnson-Lindenstrauss transform — a classic dimensionality reduction technique that preserves distances — to reduce each vector to a single sign bit per dimension.
The magic is in the estimator: QJL pairs a high-precision query with the low-precision compressed keys to reconstruct an unbiased estimate of the inner product. The errors cancel out rather than compound.
The net result: 3-bit quantization that behaves like 16-bit. The model literally cannot tell the difference.
The DeepSeek Moment Comparison
The internet was quick to call this the Pied Piper algorithm (Silicon Valley fans will appreciate that). More useful is comparing it to DeepSeek's January 2025 release.
DeepSeek-R1 showed that you could train a frontier-level reasoning model for a fraction of the cost that OpenAI spent. It crashed NVIDIA's stock 17% in a single day because investors feared the AI hardware demand story was broken.
TurboQuant is in a similar category: it makes inference cheaper without making the underlying hardware better. Less memory needed = potentially less hardware purchased.
But here's where the comparison breaks down. DeepSeek was about training cost. TurboQuant is about inference efficiency. And inference is where the actual AI economy lives — it's the running cost, not the one-time build cost.
The Jevons Paradox Counterargument
Here's what Wall Street may be getting wrong.
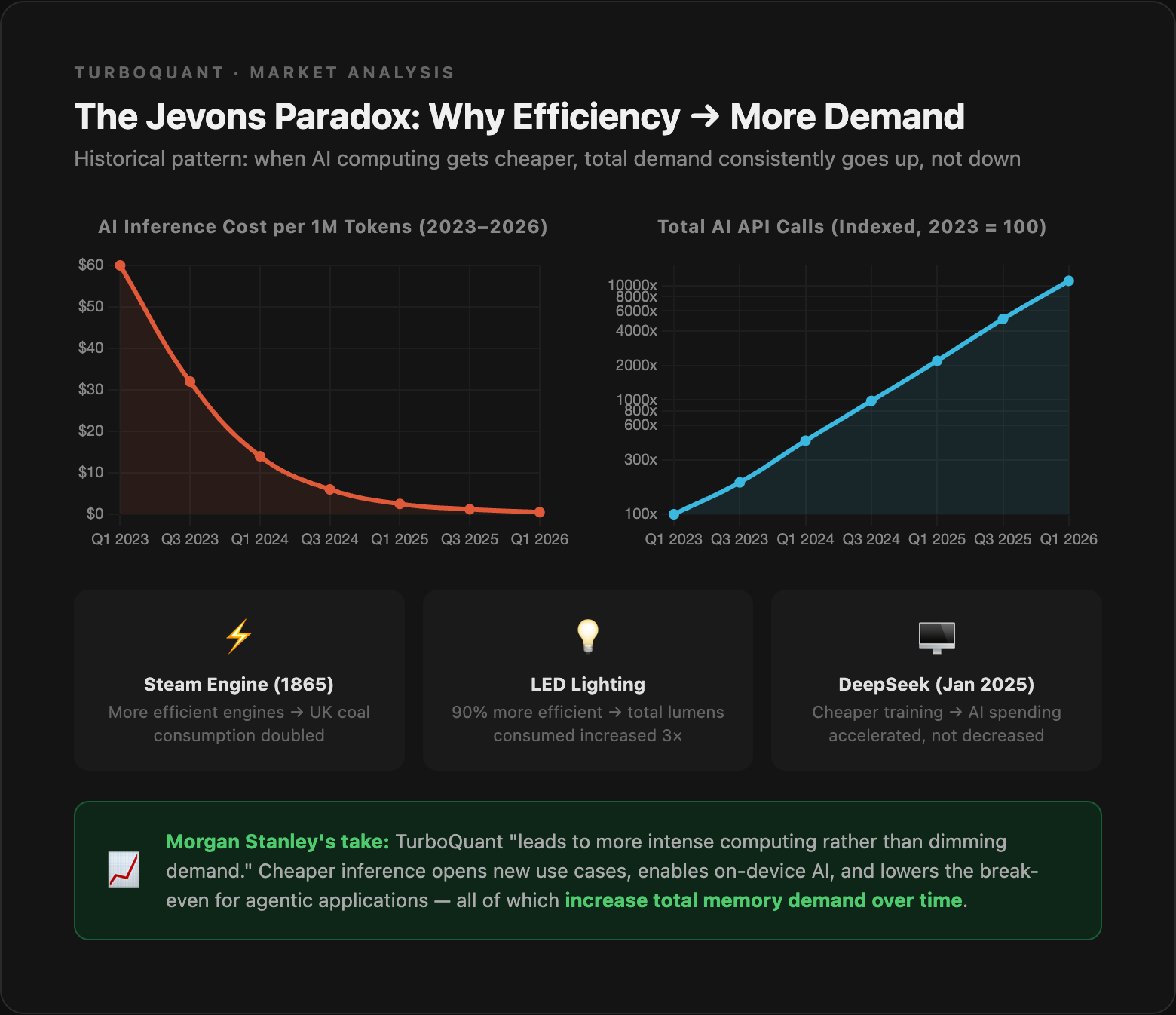
The Jevons Paradox (from 1865, when William Stanley Jevons observed that more efficient steam engines led to more coal consumption, not less) says: when you make a resource cheaper to use, total consumption often goes up.
AI is a classic Jevons candidate:
Cheaper inference means more applications become economically viable
More applications means more total compute demand
More compute demand means more memory chips sold
Morgan Stanley was on the wires today making exactly this argument, saying TurboQuant "leads to more intense computing rather than dimming demand."
There's also a new demand vector: on-device AI. One of TurboQuant's explicit use cases is making powerful LLMs small enough to run on smartphones and laptops that previously couldn't fit them in memory. Every new AI-capable device that ships because of compression advances is a new memory chip sale.
The analyst consensus agrees: 38 of 43 analysts covering Micron rate it a buy, with an average price target of $525 against today's ~$355.
What This Means for Builders
If you're running agentic systems, TurboQuant has practical implications — and they're almost entirely good.
Longer context windows, same cost. Your agents can hold more context in memory simultaneously. That 100K-token context that currently requires enormous HBM allocation? With TurboQuant-style compression, it costs 6x less. This makes long-running agentic sessions more economically viable.
Faster inference on the same hardware. The 8x attention speedup on H100s means faster token generation, which matters when your agent is chaining multiple tool calls and waiting on model outputs at each step.
Edge AI becomes real. For anyone interested in running local models — self-hosted agents, privacy-sensitive applications — TurboQuant-class compression is what makes a genuinely capable model fit on consumer hardware. That opens a lot of new use cases.
The cost curves keep bending down. Between quantization advances, mixture-of-experts architectures, speculative decoding, and KV cache compression, inference costs are on a steep downward trajectory. The economic case for agentic AI gets stronger every quarter.
The thing to watch: how fast major providers ship TurboQuant or equivalent KV cache compression into their inference pipelines. Google will almost certainly deploy it in Gemini. Others will follow. The question is timeline.
The Bottom Line
TurboQuant is a genuine technical breakthrough — not hype. Compressing KV caches to 3 bits with zero accuracy loss, no retraining, and an 8x speedup is a meaningful advance.
For the memory chip stocks, the market reaction was probably overdone. Jevons Paradox effects plus on-device AI demand create a strong counterargument.
For AI builders, this is unambiguously good news. Cheaper inference, longer context, faster responses — and it works with models you're already using.
The compression revolution in AI isn't finished. TurboQuant is one more step toward a world where running a capable AI agent is as cheap as running a database query.
TurboQuant will be presented at ICLR 2026 in Rio de Janeiro and AISTATS 2026 in Tangier. The paper and Google Research blog post are publicly available.
References
Google Research Blog: TurboQuant — Redefining AI efficiency with extreme compression
TurboQuant official site and technical overview
Tom's Hardware: Google's TurboQuant reduces AI LLM cache memory requirements by at least 6x
VentureBeat: Google's new TurboQuant algorithm speeds up AI memory 8x, cutting costs by 50% or more